概要
Mahout IN Actionのコードを頼りに、まずはコマンドとか使わずにJavaのコードからk-meansを実行してみる。
その後、bin/mahout kmeansコマンドを使って同じことをやってみる。
Mahout0.7を利用しているので、バージョンによってはクラス名が若干違うこととかあるかも。Klusterとか。
@CretedDate 2012/08/06
@Env Java7, Mahout0.7
クラスタリングするデータ
以下のような簡易データを3つにクラスタリングしてみる。
1,1 1,2 2,1 4,4 4,5 5,6 7,9 8,9,8,8
上記データをRでkmeansしてplotすると、下記のようになる。重心の数は3つ。
x = matrix( c(1, 1, 2, 4, 4, 5, 7, 8, 8, 1, 2, 1, 4, 5, 6, 9, 9, 8), ncol=2 )
cl = kmeans(x, 3)
plot(x, col=cl$cluster, pch=16, xlim=c(0, 10), ylim=c(0, 10), cex=2)
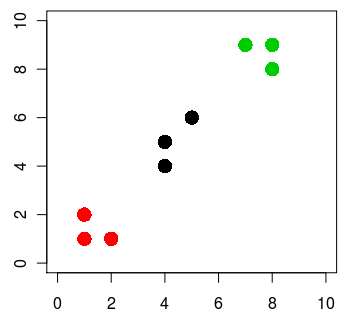
これをMahoutでやってみる。
Vectorファイルを作る
k-meansをやってくれるKMeansDriverは、インプットにHadoopのシーケンスファイル(Hadoop用にシリアライズされたデータファイル)を要求する。型はMahoutのVecotr。
とりあえず、下記のようなCSVファイルをVectorのシーケンスファイルに変えるコードを書いてみる。
1,1
1,2
2,1
4,4
4,5
5,6
7,9
8,9
8,8
VectorのInterfaceのJavaDocを見ると、Vectorにはいろんな実装が存在するようだ。RandomAccessSparseVectorとか、NamedVectorとか。
とりあえず今回はMahout IN ACTIONに倣ってRandomAccessSparseVectorを使ってみる。今回のようなデータだと他のを使う方が適切な気がするけど。
close書きたくなかったからJava7を利用。inputとoutputに指定されてるディレクトリはあらかじめ作っておくこと。
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
String input = "data/kmeans-test-data.csv";
String output = "data/kmeans-test-vector/vector.seq";
// ファイルからVectorのシーケンスファイルを作る
try (
BufferedReader reader = new BufferedReader(new FileReader(input));
SequenceFile.Writer writer = new SequenceFile.Writer(fs, conf,
new Path(output), LongWritable.class, VectorWritable.class)
) {
String line;
long counter = 0;
while ((line = reader.readLine()) != null) {
// ファイルの1行からVectorを作る
String[] c = line.split(",");
double[] d = new double[c.length];
for (int i = 0; i < c.length; i++)
d[i] = Double.parseDouble(c[i]);
Vector vec = new RandomAccessSparseVector(c.length);
vec.assign(d);
// Vectorをシーケンスファイルに出力する
VectorWritable writable = new VectorWritable();
writable.set(vec);
writer.append(new LongWritable(counter++), writable);
}
}
コード全文はこちら
これでoutputに指定したパスにファイルが生成された。
Clusterを作る
k-meansの場合は、デフォルトの重心を設定しておいてあげる必要がある。これもシーケンスファイルで渡す。
今回は適当に、1,1と4,4と9,9に重心を置いてみる。
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
String output = "data/kmeans-test-cluster/part-00000";
try (SequenceFile.Writer writer = new SequenceFile.Writer(fs, conf, new Path(output),
Text.class, Kluster.class);) {
double[][] centroids = { { 1, 1 }, { 4, 4 }, { 9, 9 } };
for (int i = 0; i < centroids.length; i++) {
Vector vec = new RandomAccessSparseVector(centroids[i].length);
vec.assign(centroids[i]);
Kluster cluster = new Kluster(vec, i, new EuclideanDistanceMeasure());
writer.append(new Text(cluster.getIdentifier()), cluster);
}
}
コード全文はこちら
Clusterの作り方は普通はこんな風に固定値は振らないけど、今回はこれで良しとする。
Canopyでクラスタリングした結果を使う方法とかはよく見かける。
k-meansの実行
じゃ、実行してみる。
KMeansDriver.run(new Path("data/kmeans-test-vector"),
new Path("data/kmeans-test-cluster"),
new Path("data/kmeans-output"),
new EuclideanDistanceMeasure(),
0.001, 10, true, 0.0, false);
コード全文はこちら
1つ目の引数にVectorファイルを指定。2つ目の引数にClusterを生成したディレクトリを指定。
3つ目の引数で指定したdata/kmeans-outputというパスに結果が出力される。出力結果もシーケンスファイルなので、バイナリアンでもない限りそのままcatしても読めない。
下記のようなコードで、結果ファイルの中身を出力させてみる。
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
try (SequenceFile.Reader reader = new SequenceFile.Reader(fs,
new Path("data/kmeans-output/clusteredPoints/part-m-00000"), conf)) {
IntWritable key = new IntWritable();
WeightedVectorWritable value = new WeightedVectorWritable();
while (reader.next(key, value)) {
System.out.println("point=" + value.getVector() + " cluster=" + key.get());
}
}
結果はこんな感じ。Rでやったのと同じ結果になったっぽい。
point={1:1.0,0:1.0} cluster=0
point={1:2.0,0:1.0} cluster=0
point={1:1.0,0:2.0} cluster=0
point={1:4.0,0:4.0} cluster=1
point={1:5.0,0:4.0} cluster=1
point={1:6.0,0:5.0} cluster=1
point={1:9.0,0:7.0} cluster=2
point={1:9.0,0:8.0} cluster=2
point={1:8.0,0:8.0} cluster=2
今回はコードを書いたけど、シーケンスファイルの内容を見る時は、seqdumperあたりを使っておいた方が楽かもしれない。
他の結果ファイルも見てみる
上の例ではclusteredPointsの下だけ読んだ。けど、k-meansした結果ディレクトリには他にもいくつかのディレクトリができている。
出力結果をtreeするとこんな感じ。
|-- _policy
|-- clusteredPoints
| |-- _SUCCESS
| `-- part-m-00000
|-- clusters-0
| |-- _policy
| |-- part-00000
| |-- part-00001
| `-- part-00002
|-- clusters-1
| |-- _SUCCESS
| |-- _policy
| `-- part-r-00000
`-- clusters-2-final
|-- _SUCCESS
|-- _policy
`-- part-r-00000
clusteredPointsには、各ポイントがどのクラスタに配置されたかが記述される。
clusters-0〜2-finalは、クラスタリングの途中経過だと思われる。試しにclusterdumpを使って中身を見てみる。
$ bin/mahout clusterdump -i file:///home/user/workspace/mahout/data/kmeans-output/clusters-0/ -o result
$ cat result
CL-0{n=0 c=[1.000, 1.000] r=[]}
CL-1{n=0 c=[4.000, 4.000] r=[]}
CL-2{n=0 c=[9.000, 9.000] r=[]}
見ての通り、clusters-0には初期設定した値が入っている。
clusters-1の値はこんな感じ。
CL-0{n=3 c=[1.333, 1.333] r=[0.471, 0.471]}
CL-1{n=3 c=[4.333, 5.000] r=[0.471, 0.816]}
CL-2{n=3 c=[7.667, 8.667] r=[0.471, 0.471]}
最後、clusters-2-final。
VL-0{n=3 c=[1.333, 1.333] r=[0.471, 0.471]}
VL-1{n=3 c=[4.333, 5.000] r=[0.471, 0.816]}
VL-2{n=3 c=[7.667, 8.667] r=[0.471, 0.471]}
clusters1と変わってない。こんな感じで重心を定めたらしい。
コマンドから実行してみる
bin/mahout kmeansコマンドを使って、同じことをやってみる。
とりあえずVectorとClusterファイルをHDFSに上げる。
$ hadoop fs -put kmeans-test-cluster .
$ hadoop fs -put kmeans-test-vector .
$MAHOUT_HOMEに移って、bin/mahoutからkmeansを実行する。
$ bin/mahout kmeans \
--input kmeans-test-vector \
--clusters kmeans-test-cluster \
--output kmeans-output \
--maxIter 10
これで--outputで指定したパスに結果が出力されている。
$ hadoop fs -ls kmeans-output
Found 3 items
drwxr-xr-x - hdfs supergroup 0 2012-08-05 19:53 /user/hdfs/kmeans-output/clusters-0
drwxr-xr-x - hdfs supergroup 0 2012-08-05 19:53 /user/hdfs/kmeans-output/clusters-1
drwxr-xr-x - hdfs supergroup 0 2012-08-05 19:53 /user/hdfs/kmeans-output/clusters-2-final
あれ、clustersしかいない。clusteredPointsはどこだ。
どうやらclusteredPointsは引数に--clusteringを加えた時にだけ出力されるらしい。
$ bin/mahout kmeans \
--input kmeans-test-vector \
--clusters kmeans-test-cluster \
--output kmeans-output \
--clustering \
--maxIter 10
これで出力された。
$ bin/mahout seqdumper -i kmeans-output/clusteredPoints
Key class: class org.apache.hadoop.io.IntWritable Value Class: class org.apache.mahout.clustering.classify.WeightedVectorWritable
Key: 0: Value: 1.0: [1.000, 1.000]
Key: 0: Value: 1.0: [1.000, 2.000]
Key: 0: Value: 1.0: [2.000, 1.000]
Key: 1: Value: 1.0: [4.000, 4.000]
Key: 1: Value: 1.0: [4.000, 5.000]
Key: 1: Value: 1.0: [5.000, 6.000]
Key: 2: Value: 1.0: [7.000, 9.000]
Key: 2: Value: 1.0: [8.000, 9.000]
Key: 2: Value: 1.0: [8.000, 8.000]
Count: 9