概要
CanopyでクラスタリングしてできたClusterを、k-meansの初期値として利用するありがちな一連の攻防をやってみる。
とりあえず簡易コードをEclipse上で動かしてみる。その後、コマンドからも叩いてみる。
@CretedDate 2012/08/06
@Env Java7, Mahout0.7
クラスタリングするデータ
わかりやすいように四隅+中央の5つに分類されそうなデータを用意する。
1,1 1,2 0,3 9,0 8,1 7,0 0,8 2,9 3,8 9,9 8,7 7,9 5,5 3,5 5,6
上記データをRでplotしてみる。
> x = matrix( c(1,1,0,9,8,7,0,2,3,9,8,7,5,3,5,1,2,3,0,1,0,8,9,8,9,7,9,5,5,6), ncol=2 )
> plot(x, pch=16, xlim=c(0, 10), ylim=c(0, 10), col="blue")
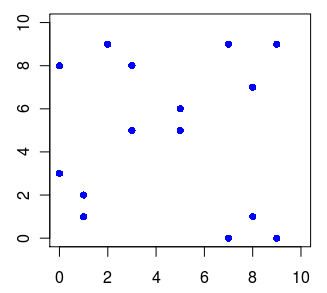
引数によって、クラスタ数が5つになるか4つになるか分からない分布だけど、とりあえずこのデータに対して実行してみよう。
シーケンスファイルを作っておく
k-meansの時と同じく、データはVectorのシーケンスファイルで渡す。
ので、上のデータのシーケンスファイルを作る。
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
String input = "data/canopy-sample-data.csv";
String output = "data/canopy-sample-vector/vector.seq";
// ファイルからVectorのシーケンスファイルを作る
try (
BufferedReader reader = new BufferedReader(new FileReader(input));
SequenceFile.Writer writer = new SequenceFile.Writer(fs, conf,
new Path(output), LongWritable.class, VectorWritable.class)) {
String line;
long counter = 0;
while ((line = reader.readLine()) != null) {
// ファイルの1行からVectorを作る
String[] c = line.split(",");
double[] d = new double[c.length];
for (int i = 0; i < c.length; i++)
d[i] = Double.parseDouble(c[i]);
Vector vec = new RandomAccessSparseVector(c.length);
vec.assign(d);
// Vectorをシーケンスファイルに出力する
VectorWritable writable = new VectorWritable();
writable.set(vec);
writer.append(new LongWritable(counter++), writable);
}
}
コード全文はこちら
次にinputに指定しているパスに、下記のようなCSVを用意しておく。
1,1
1,2
0,3
9,0
8,1
7,0
0,8
2,9
3,8
9,9
8,7
7,9
5,5
3,5
5,6
これで実行すると、outputで指定したパスにシーケンスファイルができる。
Canopyさんを動かす
あとは上で作ったファイルを引数で指定して、org.apache.mahout.clustering.canopy.CanopyDriverを叩けばいい。
但し、Canopyさんは動かす際にいろいろ引数を要求する。とりあえず下記のあたりは指定しないといけない。
input : 入力パス(Vectorのシーケンスファイル)
output : 出力パス
t1 : 半径その1
t2 : 半径その2
今回は距離的に見て、t1は2.0、t2は4.0くらいを指定してみる。
CanopyDriver.run(new Path("data/canopy-sample-vector"),
new Path("data/canopy-output"),
new EuclideanDistanceMeasure(),
2.0, 4.0,
true,
0.0,
false);
コード全文はこちら
結果を見てみる。
$ bin/mahout clusterdump -i file:///home/user/workspace/mahout/data/canopy-output/clusters-0-final/ -o result
$ cat result
C-0{n=1 c=[1.000, 1.500] r=[]}
C-1{n=1 c=[8.500, 0.500] r=[]}
C-2{n=1 c=[1:8.000] r=[]}
C-3{n=1 c=[9.000, 9.000] r=[]}
C-4{n=1 c=[5.000, 5.500] r=[]}
四隅と中央でちゃんと5つの重心ができた。よくやった。
ちなみにt1とt2を4.0と6.0にしたところ、結果は4つになった。
C-0{n=1 c=[0.667, 2.000] r=[]}
C-1{n=1 c=[8.000, 0.333] r=[]}
C-2{n=1 c=[1.667, 8.333] r=[]}
C-3{n=1 c=[8.000, 8.333] r=[]}
Canopyさんの結果からk-meansする
前の前の項で生成したシーケンスファイルと、前の項で生成したclusters-0-finalを使って、k-meansしてみる。
KMeansDriver.run(new Path("data/canopy-sample-vector"),
new Path("data/canopy-output/clusters-0-final"),
new Path("data/canopy-kmeans-output"),
new EuclideanDistanceMeasure(),
0.001, 10, true, 0.0, false);
結果を見てみる。
$ bin/mahout seqdumper -i file:///home/user/workspace/mahout/data/canopy-kmeans-output/clusteredPoints/
Key class: class org.apache.hadoop.io.IntWritable Value Class: class org.apache.mahout.clustering.classify.WeightedVectorWritable
Key: 0: Value: 1.0: [1.000, 1.000]
Key: 0: Value: 1.0: [1.000, 2.000]
Key: 0: Value: 1.0: [1:3.000]
Key: 1: Value: 1.0: [0:9.000]
Key: 1: Value: 1.0: [8.000, 1.000]
Key: 1: Value: 1.0: [0:7.000]
Key: 2: Value: 1.0: [1:8.000]
Key: 2: Value: 1.0: [2.000, 9.000]
Key: 2: Value: 1.0: [3.000, 8.000]
Key: 3: Value: 1.0: [9.000, 9.000]
Key: 3: Value: 1.0: [8.000, 7.000]
Key: 3: Value: 1.0: [7.000, 9.000]
Key: 4: Value: 1.0: [5.000, 5.000]
Key: 4: Value: 1.0: [3.000, 5.000]
Key: 4: Value: 1.0: [5.000, 6.000]
Count: 15
予定通り、四隅+中央でクラスタリングされている。
重心はこんな感じ。
$ bin/mahout clusterdump -i file:///home/masato/workspace/sample/mahout/data/canopy-kmeans-output/clusters-2-final/ -o result
$ cat result
VL-0{n=3 c=[0.667, 2.000] r=[0.471, 0.816]}
VL-1{n=3 c=[8.000, 0.333] r=[0.816, 0.471]}
VL-2{n=3 c=[1.667, 8.333] r=[1.247, 0.471]}
VL-3{n=3 c=[8.000, 8.333] r=[0.816, 0.943]}
VL-4{n=3 c=[4.333, 5.333] r=[0.943, 0.471]}
コマンドから実行する
コードから実行はできたので、次は同じことをコマンドから叩いてHadoop上で動かしてみる。
まずはコードから実行した時に作ったVectorファイルをHDFS上に上げておく。
$ hadoop fs -put data/canopy-sample-vector/vector.seq .
次にcanopyを実行する。
$ bin/mahout canopy \
--input vector.seq \
--output canopy-output \
-t1 2.0 \
-t2 4.0 \
--distanceMeasure org.apache.mahout.common.distance.EuclideanDistanceMeasure
結果を見てみる。
$ bin/mahout clusterdump -i canopy-output/clusters-0-final -o result
$ cat result
C-0{n=1 c=[1.000, 1.500] r=[]}
C-1{n=1 c=[8.500, 0.500] r=[]}
C-2{n=1 c=[1:8.000] r=[]}
C-3{n=1 c=[9.000, 9.000] r=[]}
C-4{n=1 c=[5.000, 5.500] r=[]}
コードから動かした時と同じく、5つにクラスタリングされている。
あとはこれを素にしてk-meansを動かしてみる。
$ bin/mahout kmeans \
--input vector.seq \
--clusters canopy-output/clusters-0-final \
--output canopy-kmeans-output \
--clustering \
--maxIter 10
結果を見てみる。
$ bin/mahout seqdumper -i canopy-kmeans-output/clusteredPoints
Key class: class org.apache.hadoop.io.IntWritable Value Class: class org.apache.mahout.clustering.classify.WeightedVectorWritable
Key: 0: Value: 1.0: [1.000, 1.000]
Key: 0: Value: 1.0: [1.000, 2.000]
Key: 0: Value: 1.0: [1:3.000]
Key: 1: Value: 1.0: [0:9.000]
Key: 1: Value: 1.0: [8.000, 1.000]
Key: 1: Value: 1.0: [0:7.000]
Key: 2: Value: 1.0: [1:8.000]
Key: 2: Value: 1.0: [2.000, 9.000]
Key: 2: Value: 1.0: [3.000, 8.000]
Key: 3: Value: 1.0: [9.000, 9.000]
Key: 3: Value: 1.0: [8.000, 7.000]
Key: 3: Value: 1.0: [7.000, 9.000]
Key: 4: Value: 1.0: [5.000, 5.000]
Key: 4: Value: 1.0: [3.000, 5.000]
Key: 4: Value: 1.0: [5.000, 6.000]
Count: 15
うまくできたようだ。