plot
作ったファイルを読み込んでplotで視覚化してみる。
# Rの立ち上げ
$ R
# ファイルを読み込む
> x <- read.csv('players.txt', sep="\t" )
# 年俸(2列目)と身長(7列目)を使ってplotしてみる
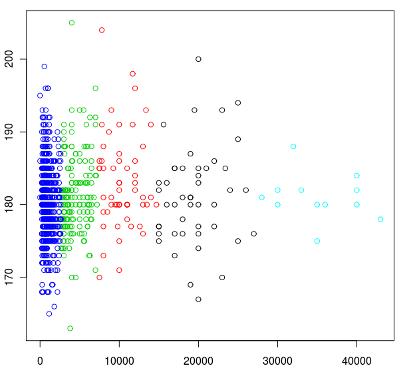
> plot( x[ c(2, 7) ] )
Y軸が身長、X軸が年俸。見るからになんの相関もなさそうな図。
でも、勉強のためにここからいろいろ数字は出してみることにする。
本稿はRを学び始めたプログラマが学習中に残したメモ書きです。
1回目の今回は、Rさんに「プロ野球選手の身長と年俸の間にはなんらかの関係があったりしない?」という質問をしてみようとした様子が記録されています。
母数が少ない上にそもそも両者に強い相関が見られるとは思えない、という条件の元にスタートしているので結果は芳しくないものとなります。そもそも広島と巨人の年俸を同列に扱ってはいけないと思うんだ。
Rのバージョンは2.10.1。OSはUbuntu10.04。
Ubuntuの場合はapt-getでインストールできる。特にレポジトリを追加する必要もなかった。
$ apt-get install r-base
利用するデータはプロ野球データFreak様に頼ることにする。12球団全員分の年俸(推定金額。報酬加算金は含まれてないよ)が掲載されている。
球団ごとにまとまっているので、全12ページ。12回ならスクレイピングするほどでもないので、手でコピーして適当にデータを整形し、こんな内容のファイルを作る。
岩瀬 仁紀 45000 投手 14 37 1974/11/10 181 85 AB型 左左 愛知 小笠原 道大 43000 内野手 16 38 1973/10/25 178 83 A型 右左 千葉 藤川 球児 40000 投手 14 31 1980/07/21 184 86 O型 右左 高知 城島 健司 40000 捕手 14 35 1976/06/08 182 89 A型 右右 長崎 阿部 慎之助 40000 捕手 12 33 1979/03/20 180 97 A型 右左 千葉 林 昌勇 36000 投手 5 35 1976/06/04 180 80 O型 右右 韓国 ・ ・ ・
全901行。練習用のデータとしてはちょうど良いサイズ。
作ったファイルを読み込んでplotで視覚化してみる。
# Rの立ち上げ
$ R
# ファイルを読み込む
> x <- read.csv('players.txt', sep="\t" )
# 年俸(2列目)と身長(7列目)を使ってplotしてみる
> plot( x[ c(2, 7) ] )
Y軸が身長、X軸が年俸。見るからになんの相関もなさそうな図。
でも、勉強のためにここからいろいろ数字は出してみることにする。
help()でヘルプが見れるらしい。
試しに、作成したtsvファイルを読みこむ際に使った「read.csv」という関数のhelpを表示してみる。
help( read.csv )
結果
read.table package:utils R Documentation
Data Input
Description:
Reads a file in table format and creates a data frame from it,
with cases corresponding to lines and variables to fields in the
file.
Usage:
<以下略>
こんな感じでmanみたいなhelpが表示される。
前に?を付けても見れる。こっちの方がタイプ数が少なくて楽か。
?read.csv
プロ野球選手の平均身長はいくつだろう。
# 身長の最小 => 163(楽天の内村賢介内野手) min(x[7]) # 身長の最大 => 205(カープのミコライオ投手) max(x[7]) # 身長の平均 => 180.7725(ちなみに20代の日本男子の平均身長は171〜172cmくらい) mean(x[7]) # まとめていろいろ出す(最小、第一四分位点、中央値、平均値、第三四分位点、最大) summary(x[7]) Min. :163.0 1st Qu.:178.0 Median :180.0 Mean :180.8 3rd Qu.:184.0 Max. :205.0
meanだと180.8。medianだと180.0。180cm近辺の選手が多いようだ。
次に170後半の選手はサバ読んで180cmって公称するケースもあるとか聞いたことがある。実際に180cmの選手は901人中129人(179cmは51人、181cmは61人)と他より少し多めになってる。
nrow( subset(x, x[7] == 180) ) [1] 129
histと書くとヒストグラムが出せるらしい。
hist( x[,7] )
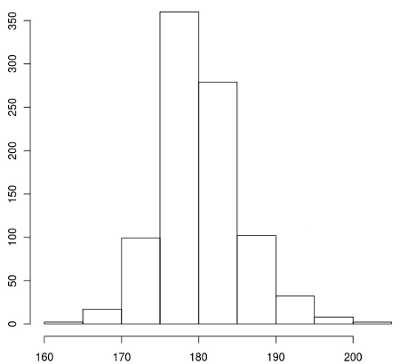
x軸が身長で、y軸が人数。180cmは一番高くなってるとこに含まれる。
175〜184cmの選手の身長の分布を見て、180cmの突出具合を見てみる。
hist( subset(x, x[7] > 174 & x[7] < 185 )[,7] )
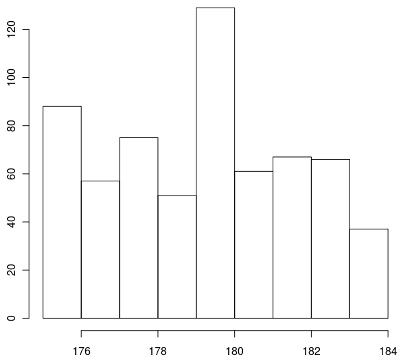
こうして見ると177〜179cmの選手が軽くサバを読んでいたり、181cmの選手が面倒だから180cmと申告していてるケースがあるのではないかと想像される。
下記URLを参考に、最小二乗法で線でも引いてみる。
> plot( x[ c(2, 7) ] ) > z <- lsfit((x[,2]), (x[,7])) > abline(z, col="red")
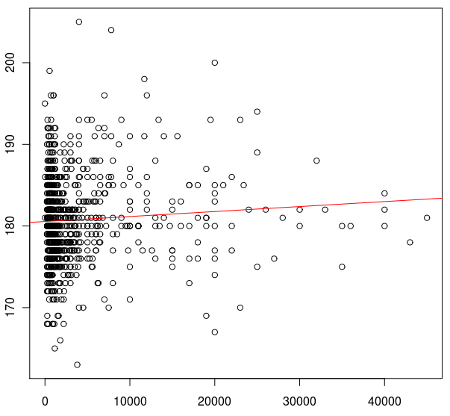
ほぼ水平。あまり意味のない線。
これが「年俸と年齢」のような関連がありそうな数値で出すとこうなる。
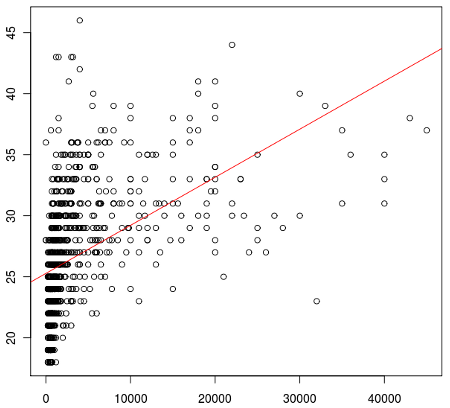
当然ながら身長と比べれば少しは関係がある。
ちなみに右下のはずれた場所にポツンといるのは、田中将大投手。23歳で年俸3億2000万。左上の年齢的に離れた場所にいるのが山本昌投手。御歳46で絶賛先発ローテ中。特別な選手はやはり目立つ。外れ値扱いしたくなるくらい。
クラスタリング用の関数も用意されてるらしいので試してみる。k-meansの場合は、こんな風に書くらしい。
# 5個でクラスタリングしてみる cl <- kmeans( x[ c(2, 7)], 5 ) plot( x[c(2, 7)], col=cl$cluster )
結果はこんな感じ。特に意味がある結果というわけではない。