全角片仮名と全角平仮名の変換をした際に悩んだこと
概要
ひらがなとカタカナをプログラムで相互に変換しようとした時に、何かと悩むことが多かったので悩ましかった点をまとめてみた。
結局、どう変換するのが良いものやら分からぬまま中途半端に調査終了。はてさて、どうしたものか。
あと文字コード表は、unicode.org と charset.7jp.netを参照しました。
結局、どう変換するのが良いものやら分からぬまま中途半端に調査終了。はてさて、どうしたものか。
あと文字コード表は、unicode.org と charset.7jp.netを参照しました。
主な悩みどころ
- 「ぁ~ん」を変換するのは楽だけど、Shift_JISは少し注意(文字コードはどこまで対応しよう)
- 最大の悩みどころは、 「ヴ」をどうするか
- 「ゝ」「ヽ」あたりは変換しようか
- 小文字の 「ヵ」と 「ヶ」はどうしたものか
- ワ行に濁点が付いた文字は分解して変換すべきか
- 「より」と「コト」を意味するあの文字は、「ヨリ」と「こと」に変換した方がいいだろうか
Unicodeの文字コード表のHIRAGANAとKATAKANA
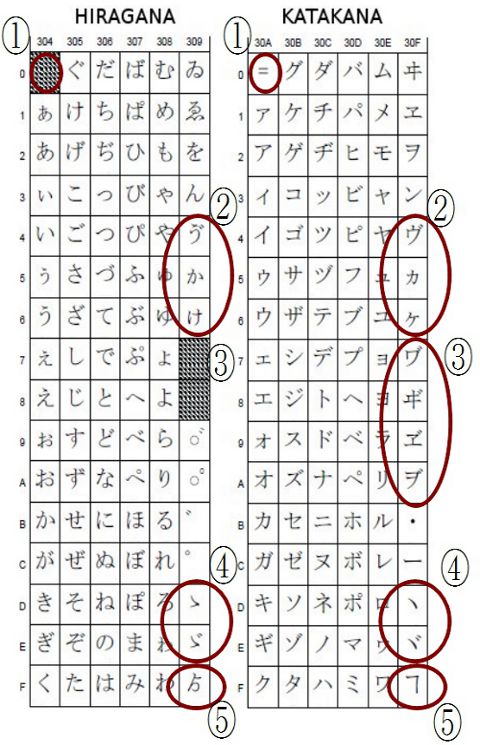
UnicodeのHIRAGANAとKATAKANAにはこんな文字が登録されている。まずはこれをさらっと見て悩みそうなポイントをピックアップ。
|
小文字の「ぁ」~「ん」までは並び順が一致しているので簡単に変換できそう。 (1) 一番左上(KATAKANAは「=」が設定されている)ところは変換する必要もなさそうなので無視して良さそう。 (2) 平仮名の「う」に濁点とかいう、環境によって化けそうな文字が設定されている。どうしたものか。 そしてその下には、平仮名の小文字の「か」と「け」。これ、一般的な環境で表示されるのだろうか。それ以前に、これって平仮名なんだろうか。 (3) カタカナの「ワ行」に濁点が付いたヤツらがいる。こんな文字使われてるの見たことないのだけど・・・。 (4) 「こゝろ」とか「スヽメ」みたいな使われ方をする文字がいる。これはShift_JISやEUC-JPにもいるし、対応すべきだろうか。 (5) まず、聞こう。一番右下のヤツ、こいつらは文字か? 「より」と「コト」と読む? 見たことないよ。 平仮名と片仮名の変換という命題を与えられた時、こいつらのことは考えるべき? |
EUC-JPの平仮名と片仮名
|
見ての通り、EUC-JPはUnicodeと同じく「ぁ~ん」までは同じ並び順になっているので、変換は楽そうです。 問題になりそうなのが、「ヴ」「ヵ」「ヶ」の3つ。 この3つは平仮名には存在しません。コード表を見た限りでは、Unicodeにあるような平仮名版の文字も用意されていません。 UnicodeにあってEUC-JPにない文字
「ゝ」や「ヽ 」は平仮名・片仮名のところにはいませんが、記号が定義されているあたりのA1B3~A1B6にいます。 |
Shift_JISの平仮名と片仮名
Shift_JISも「ぁ~ん」の並び順は変わりません。平仮名は「ぁ~ん」のみ、片仮名は「ァ~ン」と「ヴ 」「ヵ」「ヶ」というお馴染みの3文字が設定されています。
使用されている文字はEUC-JPと同じなので、詳しいコードの並びについては割愛。平仮名は829F~8283の間に設定されています。片仮名は8349~8696の間に設定されています。
注意すべき点として、平仮名は「ぁ~ん」まで連番になっているのですが、片仮名に罠がしかけてあります。
| 70 | 71 | 72 | 73 | 74 | 75 | 76 | 77 | 78 | 79 | 7A | 7B | 7C | 7D | 7E | 7F | 80 | 81 | 82 | 83 | 84 | |
| 83 | パ | ヒ | ビ | ピ | フ | ブ | プ | ヘ | ベ | ペ | ホ | ボ | ポ | マ | ミ | ム | メ | モ | ャ | ヤ |
見ての通り、7Fが空になっています。ということは、Shift_JISの場合は「'ァ' + 'む' - 'ぁ' = 'ム'」という式が成り立たなくなります。文字列を内部的にShift_JISで持ってる言語というのは最近はあまり見かけないので、気にする機会は少なそうだけど。
ヴを平仮名に変換する時はどうするべかな
文字コード表を見て回ってみて、どう始末をつけて良いか一番難しそうなのが「ヴ」の変換。マイナー文字は非対応でも良いかもしれないけど、ヴは一般的に使われる文字なので対応しないわけにはいかない。
EUC-JPとShift_JISには平仮名版の「ヴ」は存在しないし、Unicodeにしても実際に表示してみると使用しているフォントによって取ってつけたような不恰好な表示がされることもある。
とりあえず現状でヴの対応は、以下が考えられる。
1. Unicodeの場合は「平仮名のヴ」(3094)に変換する
- 化けたり不恰好な文字になる可能性はあるが、それをクリアしてるなら
2. 「う」+「゛」(濁点)に分解して変換する
- この場合、逆に「う」+「゛」をカタカナに変換する場合は結合して変換すべきか
- なにげにこの「゛」も化けるケースがある
- 実行前と後で文字の長さが変わるが大丈夫か
3. 「ヴァ」→「ば」、「ヴ」→「ぶ」のように「ば行」に変換する
- 化ける危険性のない安全な変換
- 実行前と後で文字の長さが変わるが大丈夫か
- 「ヴァ」→「ば」にしてから再度カタカナに戻すと「ば」→「バ」になるというのはどうだろう
→ 引数によって上記から選べるようにするのが優しさか
EUC-JPとShift_JISには平仮名版の「ヴ」は存在しないし、Unicodeにしても実際に表示してみると使用しているフォントによって取ってつけたような不恰好な表示がされることもある。
とりあえず現状でヴの対応は、以下が考えられる。
1. Unicodeの場合は「平仮名のヴ」(3094)に変換する
- 化けたり不恰好な文字になる可能性はあるが、それをクリアしてるなら
2. 「う」+「゛」(濁点)に分解して変換する
- この場合、逆に「う」+「゛」をカタカナに変換する場合は結合して変換すべきか
- なにげにこの「゛」も化けるケースがある
- 実行前と後で文字の長さが変わるが大丈夫か
3. 「ヴァ」→「ば」、「ヴ」→「ぶ」のように「ば行」に変換する
- 化ける危険性のない安全な変換
- 実行前と後で文字の長さが変わるが大丈夫か
- 「ヴァ」→「ば」にしてから再度カタカナに戻すと「ば」→「バ」になるというのはどうだろう
→ 引数によって上記から選べるようにするのが優しさか
その他の悩み文字はどうするべかな
・「ゝ」「ヽ」 → 変換しても大丈夫そう
- 見た限り、この文字はたいていの環境で表示することができそう
- 「ゝ」は平仮名に、「ヽ」は片仮名に付くものなので、変換した方が良さげ
- 文字コードによって配置場所が違うので、後腐れないよう変換テーブルで対応したい
・小文字の 「ヵ」と 「ヶ」 → 選択肢複数
- Unicodeの場合は平仮名小文字の「か」と「け」に変換できる
- 可能だけど化けやすそう
- 平仮名大文字の「か」と「け」に変換してはどうか
- 化けないから安心
- カタカナに戻す時に「カ」と「ケ」になってしまう
- 何もしない
- そもそも「三ヶ月」のように漢字と一緒に使うものなので、「三か月」としてしまうのも微妙
- 実は何もしないのが正解なんじゃないだろうか
・ワ行に濁点 → 選択肢複数
- 昔は「ヴァ」ではなく「ワ゛」を使っていたらしい
- それならヴの扱いと同じにしとけば良いか
- 待て、「ヴ」には平仮名が存在するけど「ワ゛」には存在しないぞ
- 可能なら「ヴ」と同じ扱いにして、真似できないケースは無変換か「わ」+「゛」かな
- ていうか、こんなマイナー文字のことなんて気にしなくていいか
・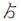 (より) と
(より) と 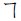 (コト) → 選択肢複数
(コト) → 選択肢複数
- 「より」は手紙で、「コト」は昔の小説(吾輩は猫であるとか)で使われているらしい
- 片仮名の「ヨリ」、平仮名の「こと」に変換するという手はある
- ていうか、やっぱりこんなマイナー文字のことなんて気にしなくていいか
・そもそも平仮名と片仮名の定義ってなんなのよ
- 言語学者に聞いてください
- 見た限り、この文字はたいていの環境で表示することができそう
- 「ゝ」は平仮名に、「ヽ」は片仮名に付くものなので、変換した方が良さげ
- 文字コードによって配置場所が違うので、後腐れないよう変換テーブルで対応したい
・小文字の 「ヵ」と 「ヶ」 → 選択肢複数
- Unicodeの場合は平仮名小文字の「か」と「け」に変換できる
- 可能だけど化けやすそう
- 平仮名大文字の「か」と「け」に変換してはどうか
- 化けないから安心
- カタカナに戻す時に「カ」と「ケ」になってしまう
- 何もしない
- そもそも「三ヶ月」のように漢字と一緒に使うものなので、「三か月」としてしまうのも微妙
- 実は何もしないのが正解なんじゃないだろうか
・ワ行に濁点 → 選択肢複数
- 昔は「ヴァ」ではなく「ワ゛」を使っていたらしい
- それならヴの扱いと同じにしとけば良いか
- 待て、「ヴ」には平仮名が存在するけど「ワ゛」には存在しないぞ
- 可能なら「ヴ」と同じ扱いにして、真似できないケースは無変換か「わ」+「゛」かな
- ていうか、こんなマイナー文字のことなんて気にしなくていいか
・
(より) と (コト) → 選択肢複数- 「より」は手紙で、「コト」は昔の小説(吾輩は猫であるとか)で使われているらしい
- 片仮名の「ヨリ」、平仮名の「こと」に変換するという手はある
- ていうか、やっぱりこんなマイナー文字のことなんて気にしなくていいか
・そもそも平仮名と片仮名の定義ってなんなのよ
- 言語学者に聞いてください
先人に学んでみよう
どうするのが正解なのか今一つ分からないので、ここは先人の行いを見て学ぼう。
平仮名と片仮名の変換が可能なソフトは、有名所だとnkf、WindowsのSDKのLCMapString、それからVBのStrConvという関数に同種の変換機能がある。
NKFの場合
・「ゝ」や「ヽ」は変換される
・小文字の「ヵ」「ヶ」は変換されない
・「コト」も変換されない
・「ゝ」や「ヽ」は変換される
・コード表にない文字(濁点付きワ行やコトなど)は消える
SDKのLCMapStringの場合
・「ヽ」系も変換される
・小文字の「ヵ」「ヶ」も平仮名に変換された
・「コト」や「ワ行の濁点付き」は変換されない
VBのStrConvの場合 → なんか化けた
・「ヴ」は放置?
・「ゝ」などの記号はちゃんと変換されている
・「ワ行の濁点付き」も試してみたけど、やはり化けて確認出来ず
まとめ
・濁点を分解・結合しているものはなかった
・「ヴ」を「ぶ」に変換しているものもなかった
・「ゝ」や「ヽ」はどれもちゃんと変換していた
・「ワ行の濁点付き」や「より」、「コト」はどれも無視していた
・平仮名小文字の「か」と「け」はnkfでは変換してなかったが、LCMapStringは変換していた
平仮名と片仮名の変換が可能なソフトは、有名所だとnkf、WindowsのSDKのLCMapString、それからVBのStrConvという関数に同種の変換機能がある。
NKFの場合
# 平仮名変換(UTF-8)
$ nkf -wh1 katakana.txt > hiragana.txt
・「ゝ」や「ヽ」は変換される
・小文字の「ヵ」「ヶ」は変換されない
・「コト」も変換されない
# 平仮名変換(EUC-JP)
$ nkf -eh1 katakana.txt > hiragana.txt
・「ゝ」や「ヽ」は変換される
・コード表にない文字(濁点付きワ行やコトなど)は消える
SDKのLCMapStringの場合
// 平仮名 → 片仮名
TCHAR* str1 =  TCHAR str2[255];
LCMapString(
GetUserDefaultLCID(), LCMAP_KATAKANA,
str1, wcslen(str1) + 1,
str2, 256
);
wprintf(L"%s", str2);
//=>
TCHAR str2[255];
LCMapString(
GetUserDefaultLCID(), LCMAP_KATAKANA,
str1, wcslen(str1) + 1,
str2, 256
);
wprintf(L"%s", str2);
//=> 
// 片仮名 → 平仮名
TCHAR* str1 =  TCHAR str2[255];
LCMapString(
GetUserDefaultLCID(), LCMAP_HIRAGANA,
str1, wcslen(str1) + 1,
str2, 256
);
wprintf(L"%s", str2);
//=>
TCHAR str2[255];
LCMapString(
GetUserDefaultLCID(), LCMAP_HIRAGANA,
str1, wcslen(str1) + 1,
str2, 256
);
wprintf(L"%s", str2);
//=> 
・「ヽ」系も変換される
・小文字の「ヵ」「ヶ」も平仮名に変換された
・「コト」や「ワ行の濁点付き」は変換されない
VBのStrConvの場合 → なんか化けた
 str = StrConv(str, VbStrConv.Hiragana) '
str = StrConv(str, VbStrConv.Hiragana) '  str = StrConv(str, VbStrConv.Katakana) '
str = StrConv(str, VbStrConv.Katakana) ' 
・「ヴ」は放置?
・「ゝ」などの記号はちゃんと変換されている
・「ワ行の濁点付き」も試してみたけど、やはり化けて確認出来ず
まとめ
・濁点を分解・結合しているものはなかった
・「ヴ」を「ぶ」に変換しているものもなかった
・「ゝ」や「ヽ」はどれもちゃんと変換していた
・「ワ行の濁点付き」や「より」、「コト」はどれも無視していた
・平仮名小文字の「か」と「け」はnkfでは変換してなかったが、LCMapStringは変換していた
結論
結局、何を正解とすれば良いのかは自分にはよく分からなかった。
とりあえず優柔不断で八方美人な自分は、引数に応じて変換モードを変えるのが優しさなんじゃないだろうかと思った。例えばこんな感じの引数を受け付けるようにするとか。
-d : 変換できない場合は分解する(ワに濁点 → わ゛)
-D : 変換できる場合も含めて「ヴ」と「ワ行」については濁点を分解
-Lk : 小文字の「ヵ」や「ヶ」も変換対象とする(Unicode限定)
-c : 可能であれば濁点を結合する(「う゛」→「ヴ」)
-e : EUC-JPで出力する
-s : Shift_JISで出力する
-w : UTF-8で出力する
-i 文字コード : 入力文字コードを指定する(UTF-8/EUC-JP/Shift_JIS)
もう1つ、たかだか平仮名と片仮名にこんなに迷ってどうする。必要に迫られたら考えればいいだろう。という結論で締めにしたいと思うのだけど、どうだろう。
とりあえず優柔不断で八方美人な自分は、引数に応じて変換モードを変えるのが優しさなんじゃないだろうかと思った。例えばこんな感じの引数を受け付けるようにするとか。
-d : 変換できない場合は分解する(ワに濁点 → わ゛)
-D : 変換できる場合も含めて「ヴ」と「ワ行」については濁点を分解
-Lk : 小文字の「ヵ」や「ヶ」も変換対象とする(Unicode限定)
-c : 可能であれば濁点を結合する(「う゛」→「ヴ」)
-e : EUC-JPで出力する
-s : Shift_JISで出力する
-w : UTF-8で出力する
-i 文字コード : 入力文字コードを指定する(UTF-8/EUC-JP/Shift_JIS)
もう1つ、たかだか平仮名と片仮名にこんなに迷ってどうする。必要に迫られたら考えればいいだろう。という結論で締めにしたいと思うのだけど、どうだろう。

